

You’ve probably heard about web scraping, right? It’s like sending an online agent to collect data from a website. But when websites get all fancy and dynamic, updating content on the fly based on user actions, that’s where deep scraping comes into play. It's not just about grabbing visible data; it's about interacting with the site, clicking buttons, filling out forms, maybe even playing a little hide and seek with data that only shows up after specific actions.
Imagine you’re trying to gather data from a site that updates its content based on user location or choices. Traditional scraping methods might just scratch the surface. That’s where deep scraping shines, allowing you to collect data that’s not immediately visible or that changes based on interactions. It’s a game-changer for businesses and analysts alike, offering a goldmine of insights and information otherwise hidden behind layers of user interaction.
If that seems too complex to achieve on your own – fear not. You can master deep scraping from dynamic websites with the least amount of manual effort using Browse AI. Ready to find out how you can scrape up to 50,000 web pages with the easiest, no-code tool? Let’s get started!
How to Achieve Deep Scraping with Browse AI
Whether or not this is your first venture into deep scraping, you might typically think of the process as something like this: Create a scraper to extract data from a website with a list of items, click on each item to open up details, capture that information, go back to the main list, and repeat with the rest. This approach can be more cumbersome than efficient given a number of factors like infinite scrolling and changing content.
That’s why Browse AI has a better alternative by connecting two robots, one to extract all the list items from a website, and the other to go into the individual detail pages to grab the remaining information. You can access this feature, called Bulk Run, right from your Browse AI dashboard. Simply create your account to get 50 credits for free, no credit card required. (By the way, if you’re unfamiliar with how to create a robot or use Browse AI, you can get an idea of the basics before you explore deep scraping.)
Now, let’s jump into how you can scrape multiple web pages simultaneously with Bulk Run:
Step 1: Setting up Robot A
Let’s call the first robot you set up as Robot A. You can activate it from your Browse AI dashboard by entering the URL of the main list of items you want to scrape. In this case, we’ll extract the list and details of Top Companies in the United States, 2023 from LinkedIn.
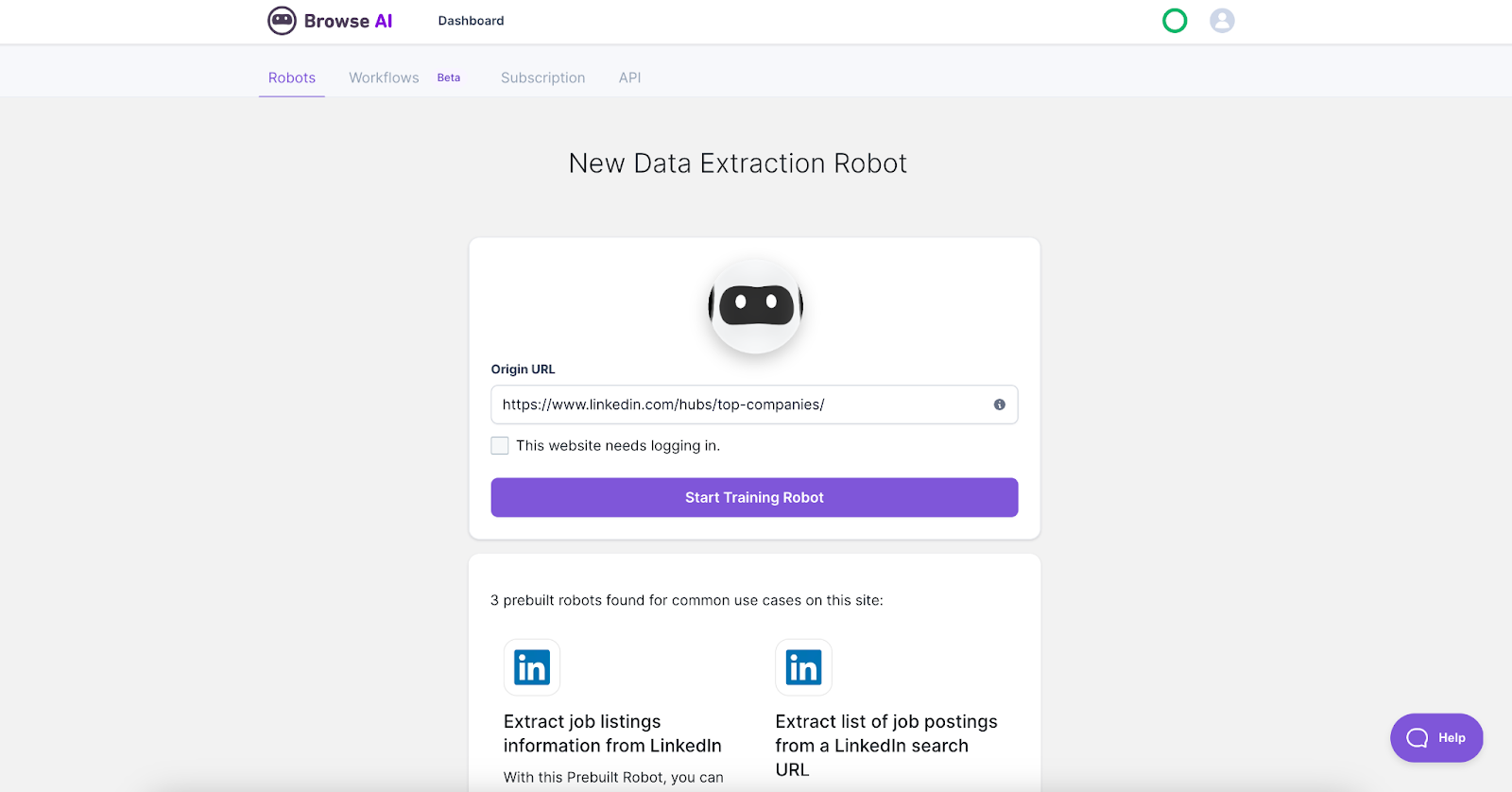
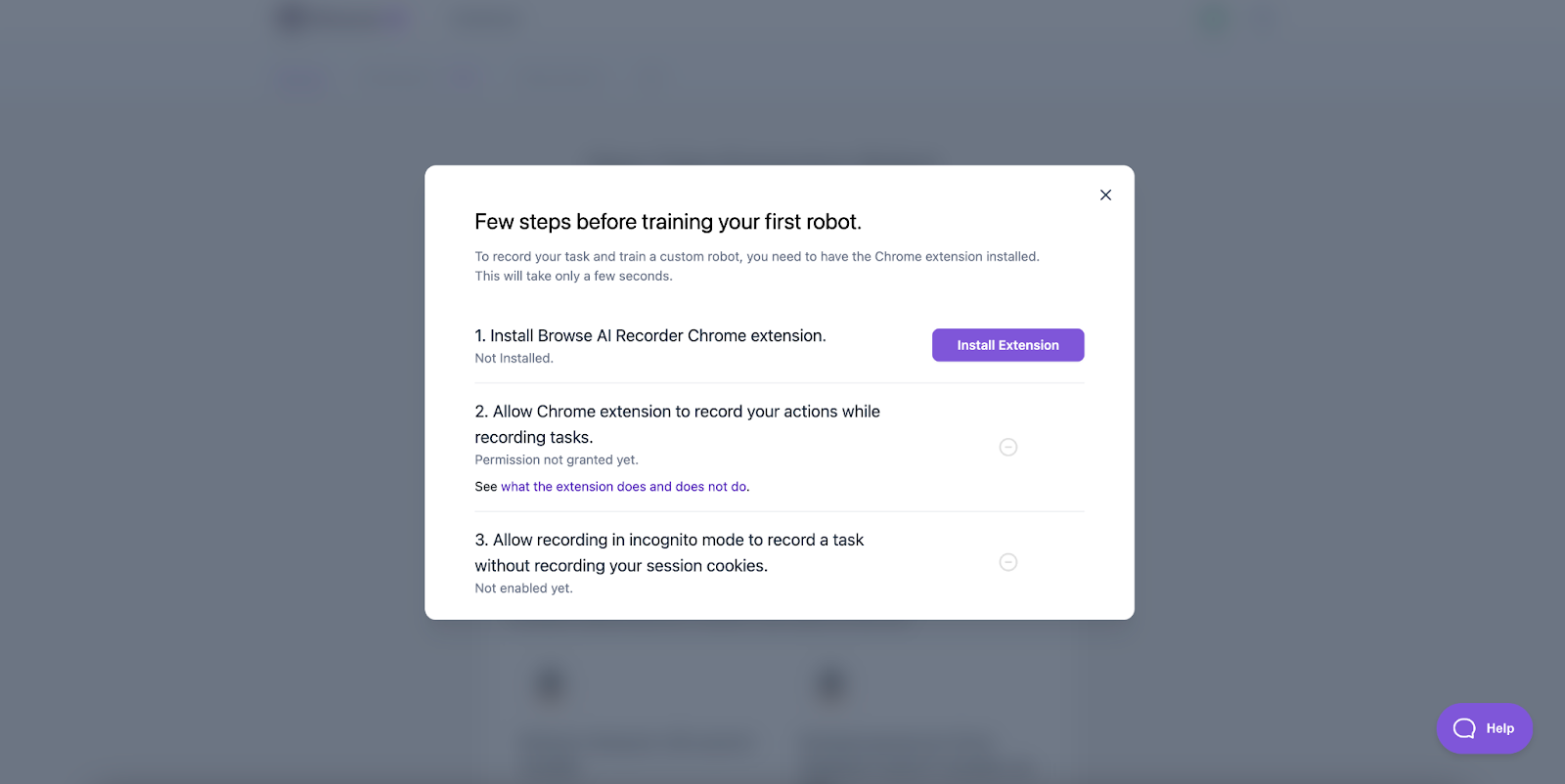
If this is your first time using Browse AI, you’ll need to install the Chrome extension. Simply follow the prompts once you click “Start Training Robot”, and choose your preferred settings.
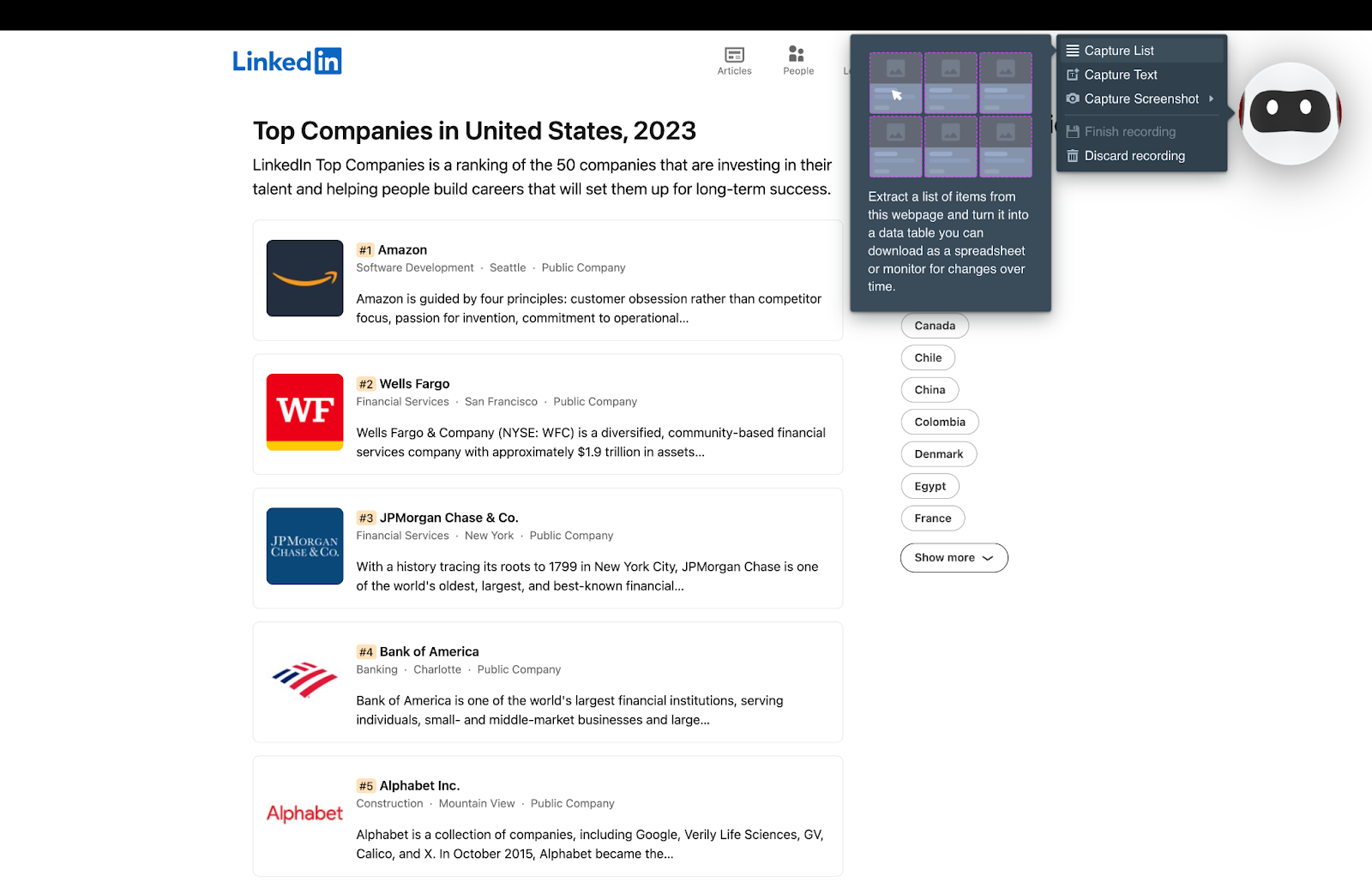
Next, you’ll see the page you want to scrape and your robot. Train your robot by selecting the type of information you want to capture (in this case it’s a list, but you can also opt for text or screenshot). Just point and click on the specific details to extract.
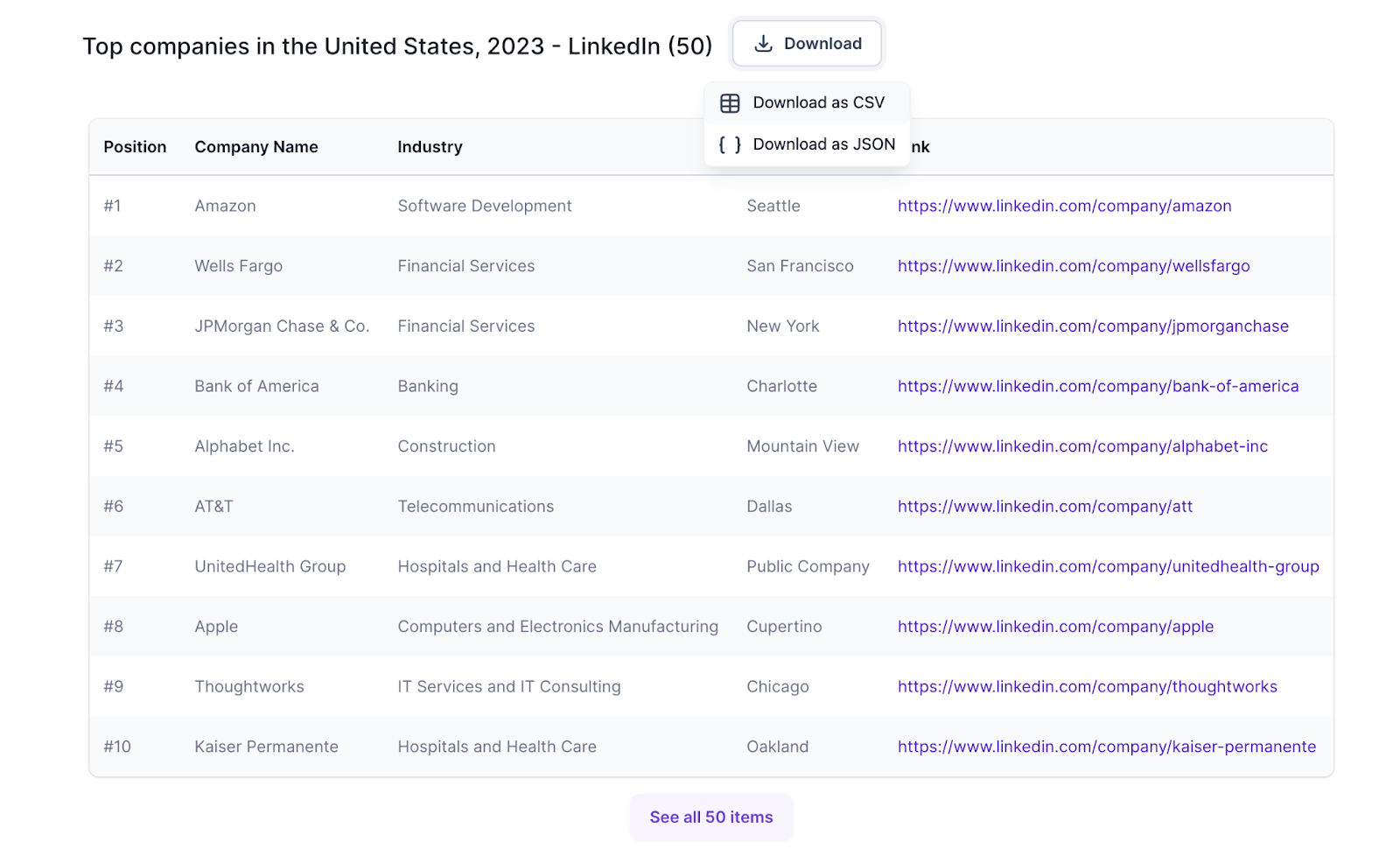
You can review the list of captured details before proceeding. Name your list, select the number of rows of data to be extracted, define the pagination type, and then click “Capture List”. Back on your dashboard, you can review the output data and confirm that it looks good or retrain your robot if something needs to be changed. Make sure you download the data as CSV (we’ll use it in the next step).
Step 2: Setting up Robot B
To create Robot B, go through the same steps as you did for Robot A. But this time, we’ll provide the URL of a specific company page on LinkedIn, to train Robot B to extract details from the list of companies we scraped using Robot A. The rest of the process remains as is – point and click on the text, review the data before capturing, and confirm that the output is as expected.
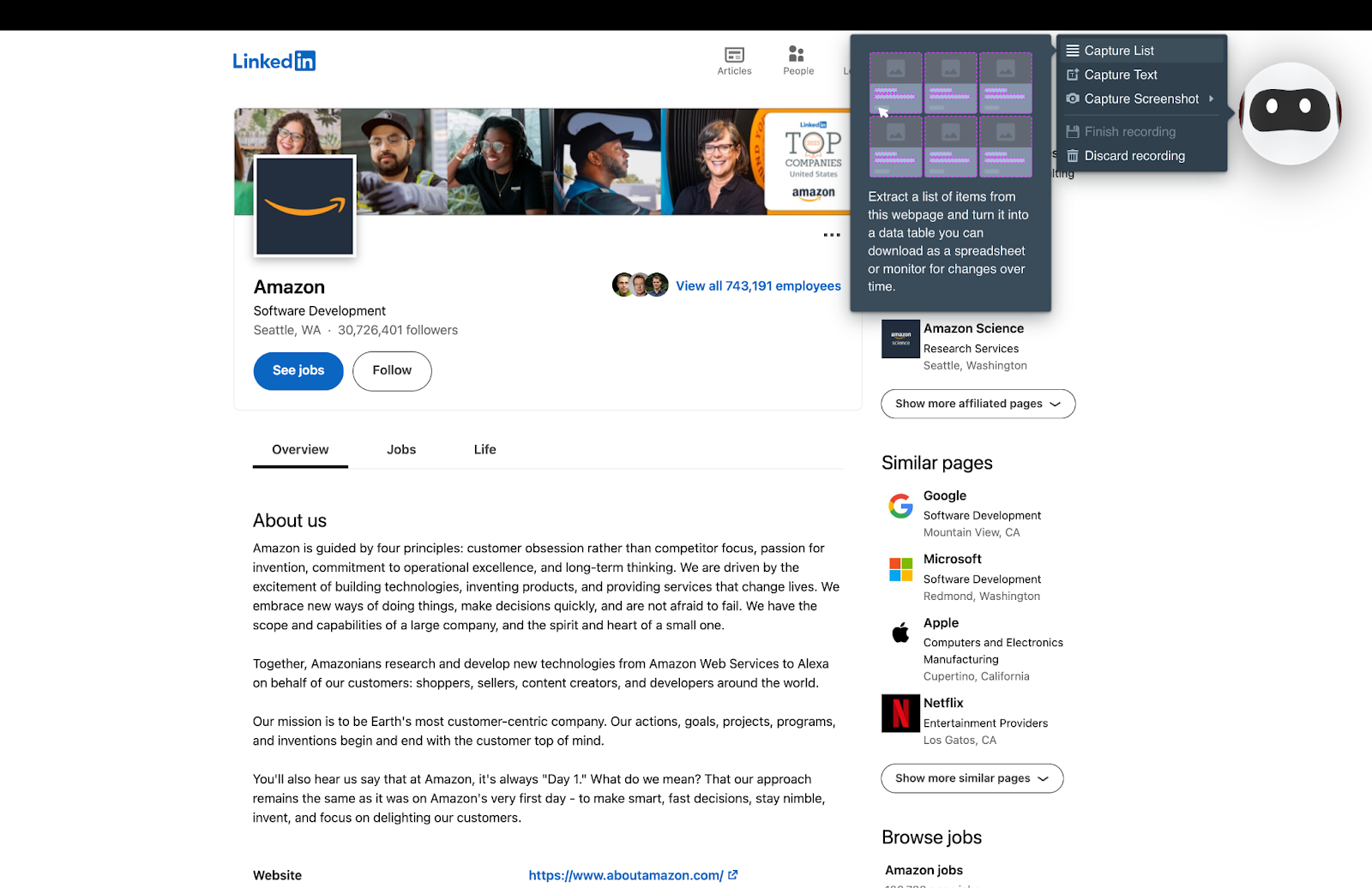
Step 3: Enabling the Bulk Run feature
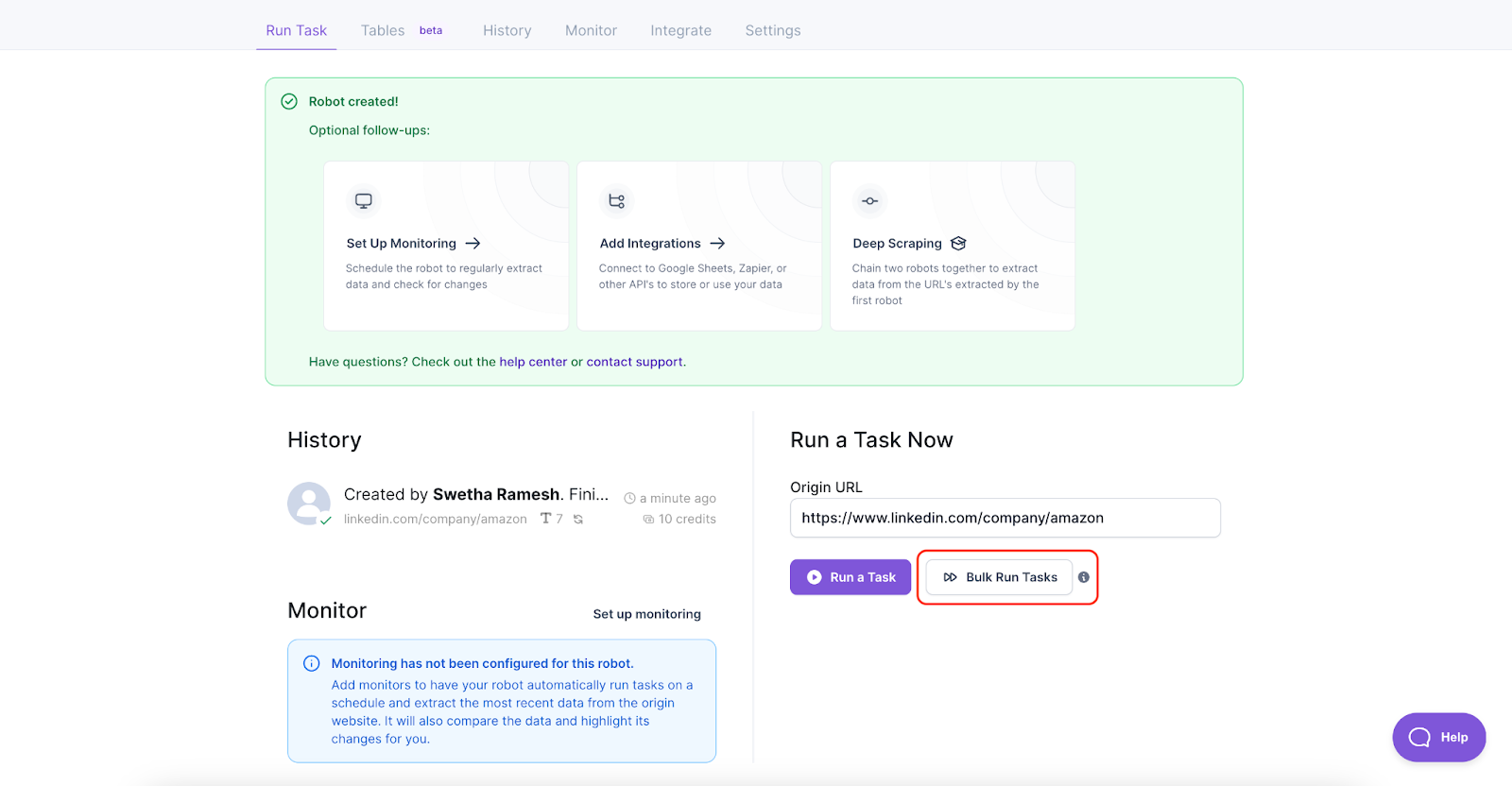
Now for the fun part – scraping the details of all 50 companies in one go using Bulk Run. What this means is that from the list of data extracted from Robot A and the training given to Robot B, you can automatically and simultaneously scrape data from each company page and turn it into a spreadsheet or database. To begin with, under the “Run Task” tab on Robot B, you’ll see the option to “Bulk Run Tasks”.
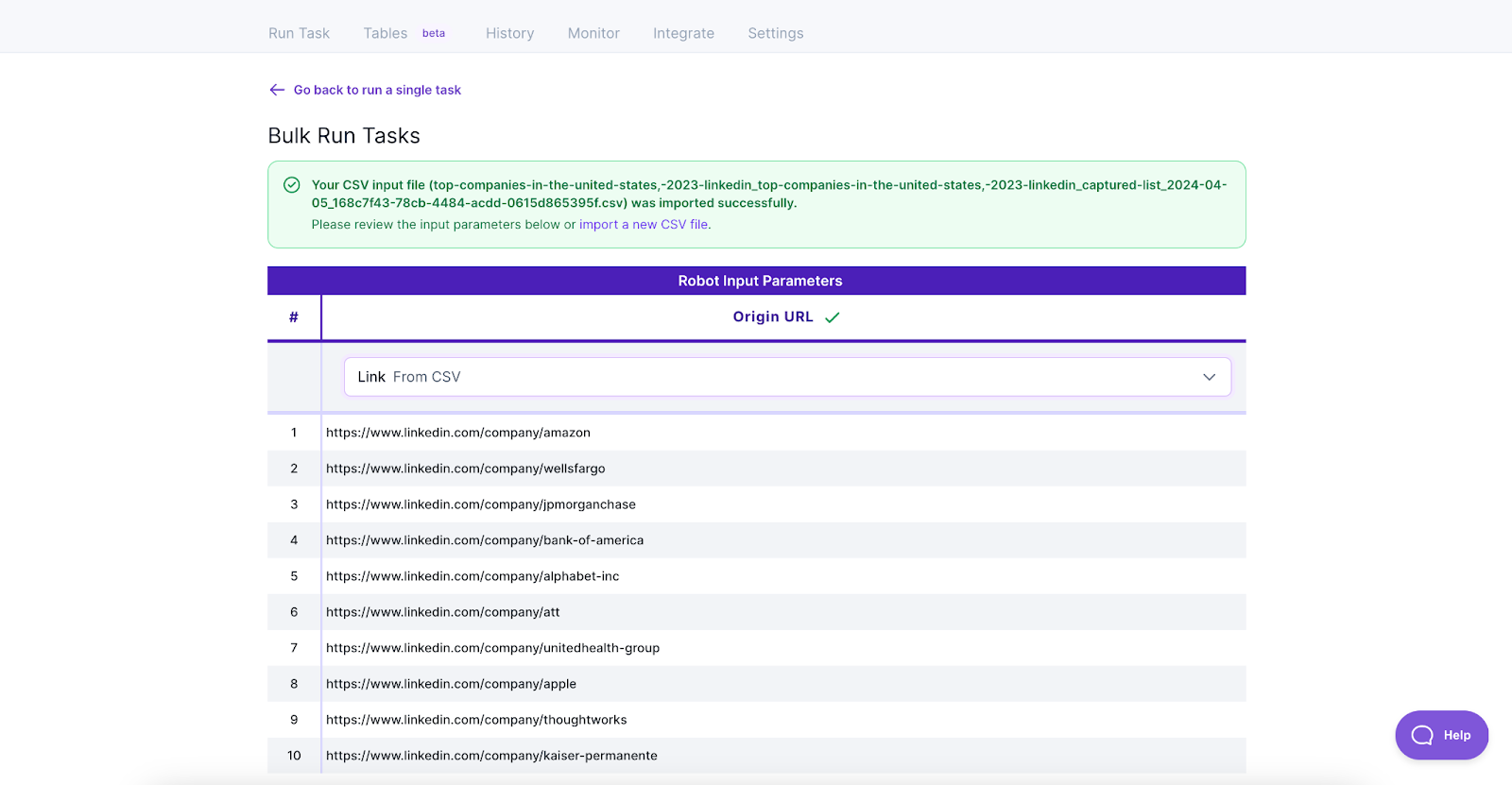
Upload the CSV you downloaded from Robot A, and then map the “Origin URL” to “Link” from the CSV.
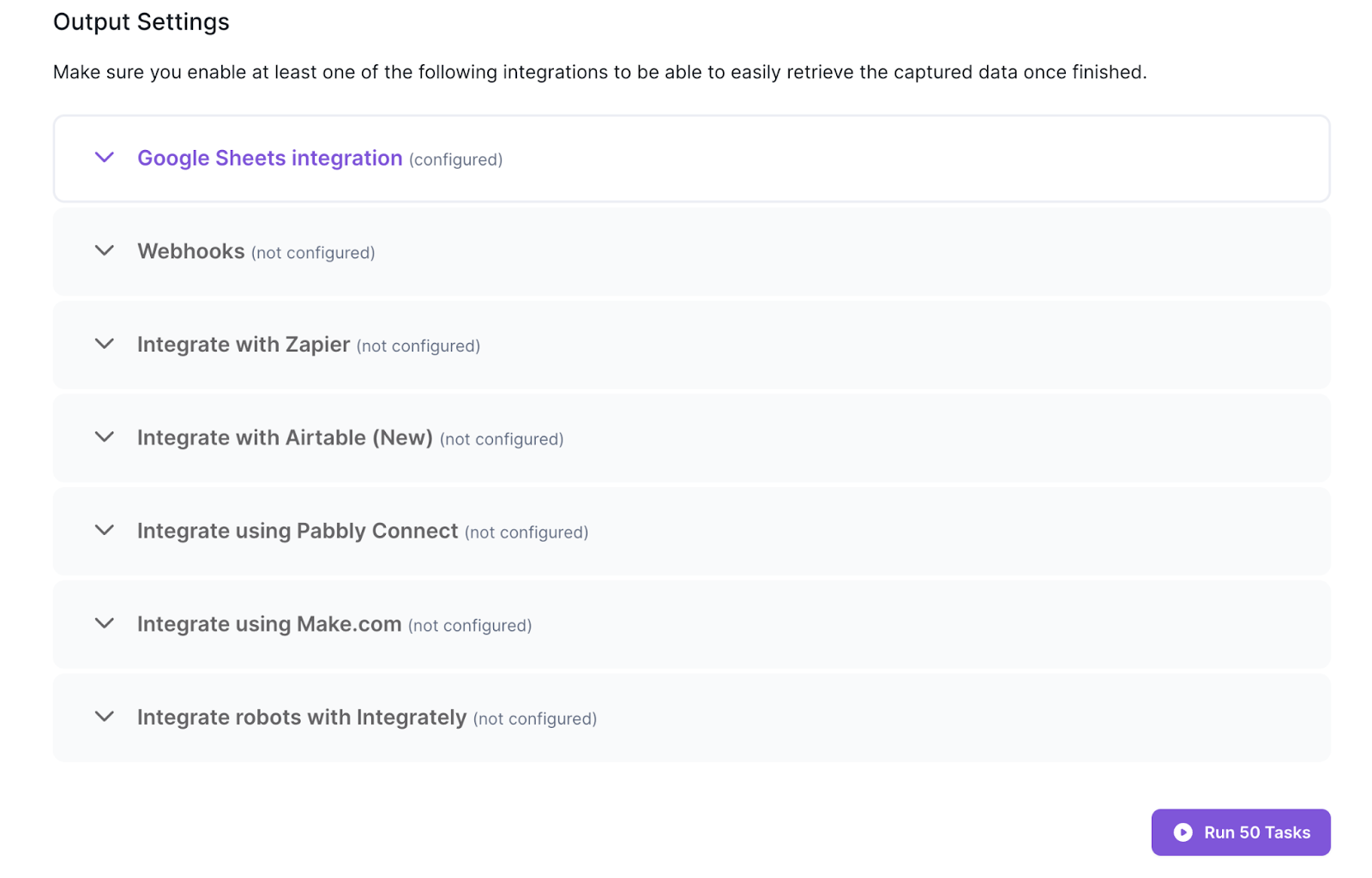
To view your data output, set up your preferred integration. Activate any integration by connecting your account and selecting the destination. Then hit “Run tasks”.
Each of the 50 tasks will be visible as your robot gets to work. You can track the status of the Bulk Run on the progress bar at the top, as well as see which ones are successful, have failed, or are in-progress. You also have the option to pause or stop the run.
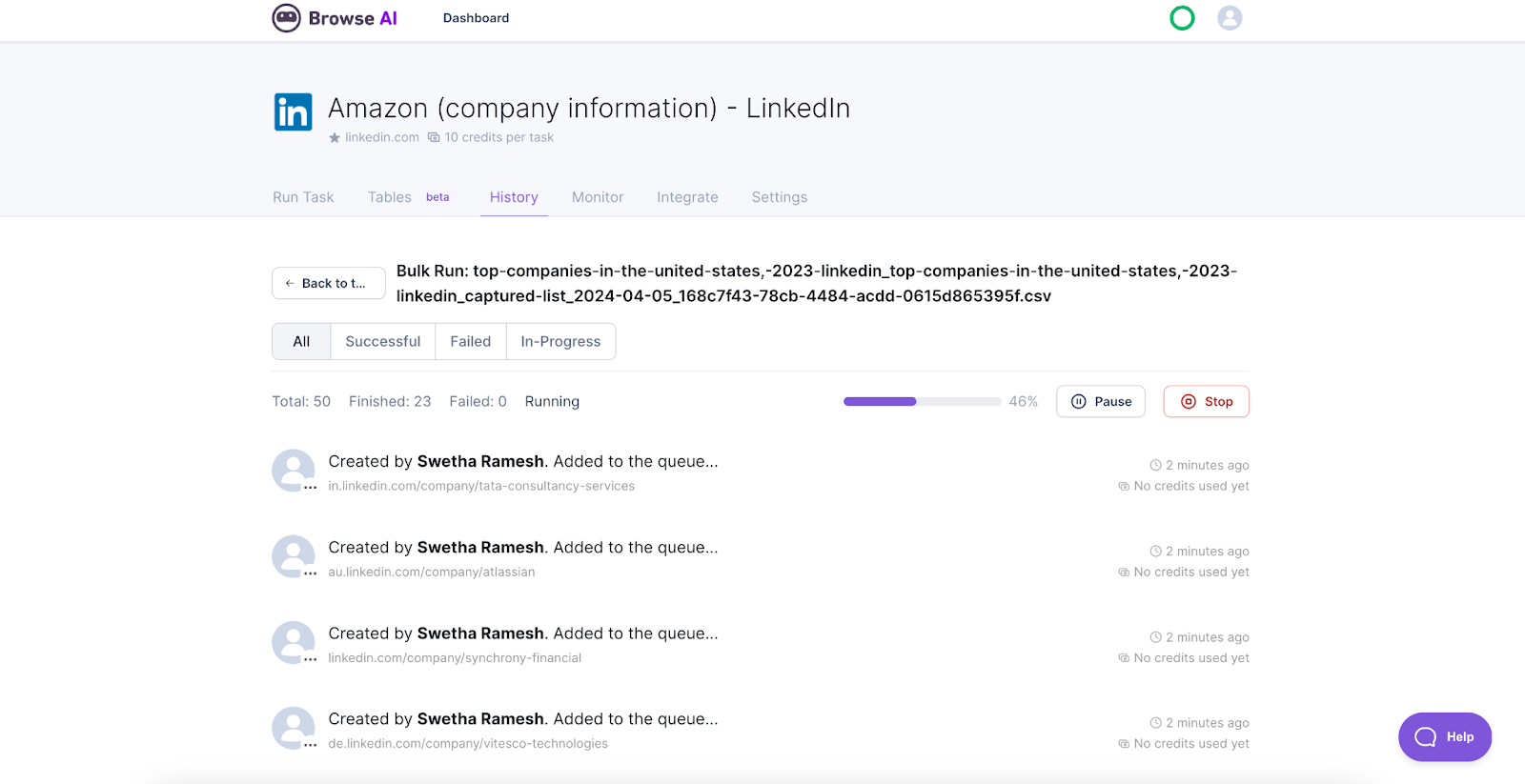
And that’s it – watch the magic happen as your spreadsheet gets populated with all the extracted data!
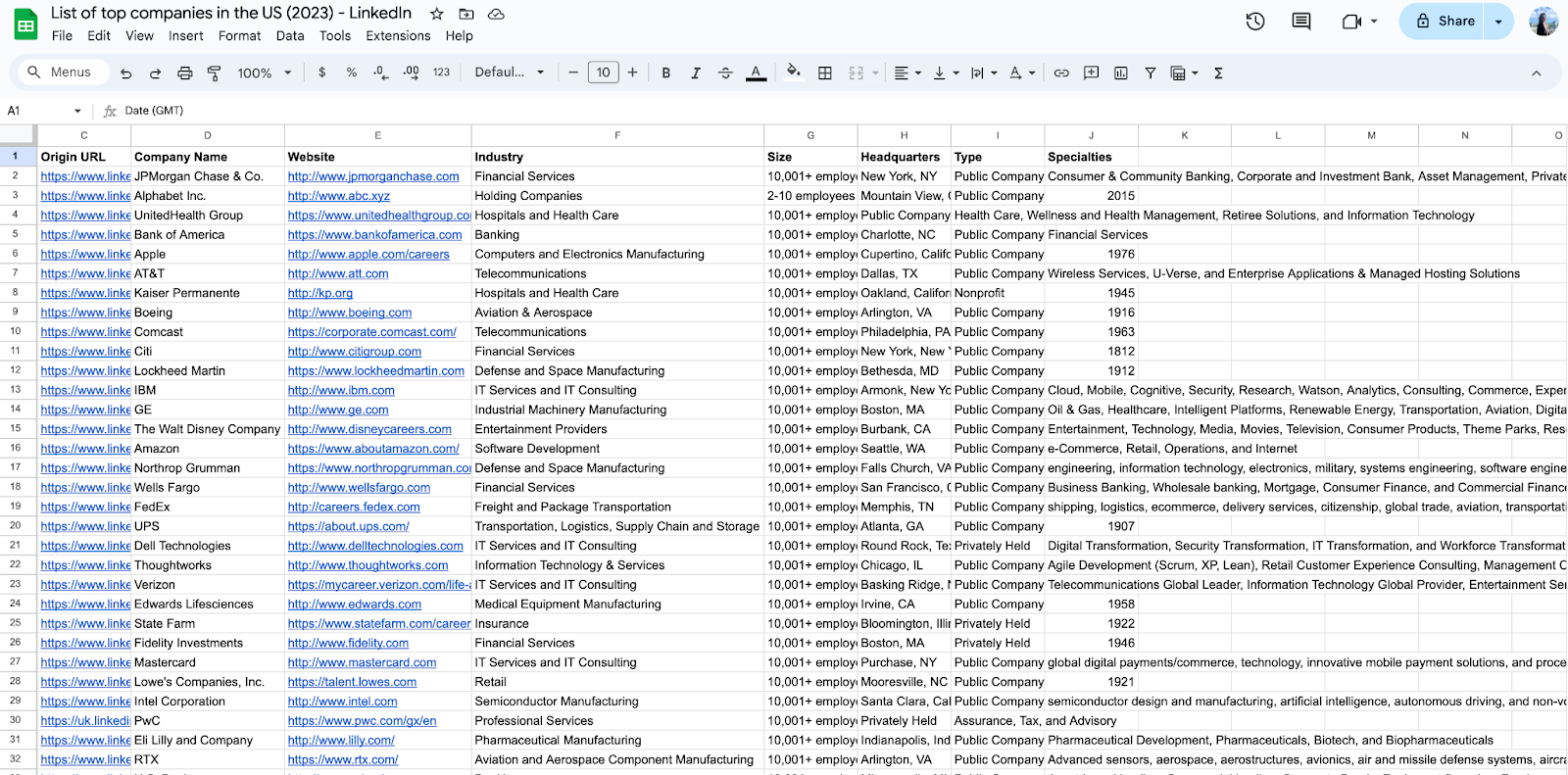
You can also view the data right from Tables on your Browse AI dashboard, where you can see your robot’s activity clearly laid out, or filter and export the data as you please.
Wrapping Up
And there you have it – a deep dive into deep scraping from dynamic websites using Browse AI. Deep scraping is more than just a technique; it's an art that blends technology, strategy, and a bit of creativity to navigate the complexities of modern websites.
Remember, the key to mastering deep scraping is patience and practice. It’s about respecting the digital ecosystem while strategically extracting the data you need. While the data you can gather are incredibly valuable, also keep in mind the importance of ethical practices. Adhering to a website’s terms of use and the legal boundaries ensures that your efforts remain respectful and productive. After all, the internet is a shared resource, and our actions as data enthusiasts should contribute positively to this ecosystem.
We hope this tutorial sparks your interest and confidence in deep scraping dynamic websites. There's a vast amount of data out there waiting to be discovered, and with the right approach, the possibilities are endless. May your data adventures lead you to insightful discoveries!
